Imagine you have a distributed cache or database running across five servers. As your user base grows, you decide to add a sixth server to improve performance and capacity.
With traditional data distribution methods, adding or removing a server often requires redistributing a large portion of the data across the entire cluster. This process can consume significant network bandwidth, increase system load, and temporarily reduce performance.
To solve this problem, modern distributed systems rely on a technique called Consistent Hashing.
Consistent Hashing is a data distribution algorithm that minimizes the amount of data that must be moved when servers are added to or removed from a cluster.
Instead of redistributing all data, only a small subset of keys needs to be relocated to the new server—or reassigned when a server leaves the cluster.
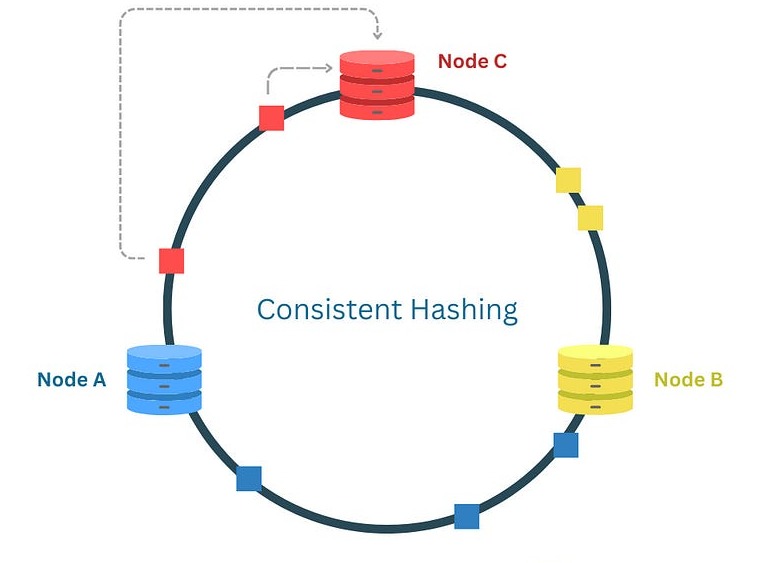
Consistent Hashing maps both servers and data keys onto a virtual structure called a Hash Ring.
The process works as follows:
This approach significantly reduces data movement during scaling operations.
New servers can be added with minimal disruption to existing data placement.
Only a small percentage of data needs to be transferred when the cluster changes.
Removing a server affects only the data assigned to that specific server rather than the entire cluster.
Scaling operations place less stress on the infrastructure and reduce service interruptions.
Consistent Hashing is widely used in:
Suppose you have four servers storing user session data.
When you add a fifth server:
Without Consistent Hashing
Most of the session data may need to be redistributed across all servers.
With Consistent Hashing
Only the subset of data that falls within the new server's assigned range is moved, while the rest of the data remains on its original servers.
In some cases, data may not be evenly distributed across physical servers, leading to load imbalance.
To address this issue, many implementations use Virtual Nodes (VNodes).
Instead of assigning each physical server a single position on the hash ring, each server is represented by multiple virtual positions. This results in a more balanced distribution of data and workloads across the cluster.
Despite its advantages, Consistent Hashing has some considerations:
No. While it is commonly used in caching platforms, it is also widely adopted in distributed databases, object storage systems, and Content Delivery Networks (CDNs).
No. It does not eliminate data movement entirely, but it dramatically reduces the amount of data that must be relocated when servers are added or removed.
Virtual Nodes improve data distribution, balance workloads more evenly, and reduce the risk of individual servers becoming overloaded.
Consistent Hashing is one of the most important algorithms in distributed systems. It enables clusters to scale up or down with minimal data movement, improving performance, reducing operational overhead, and maintaining high availability during infrastructure changes.
") United Arab Emirates (Arabic)
United Arab Emirates (Arabic)") Worldwide (English)
Worldwide (English)